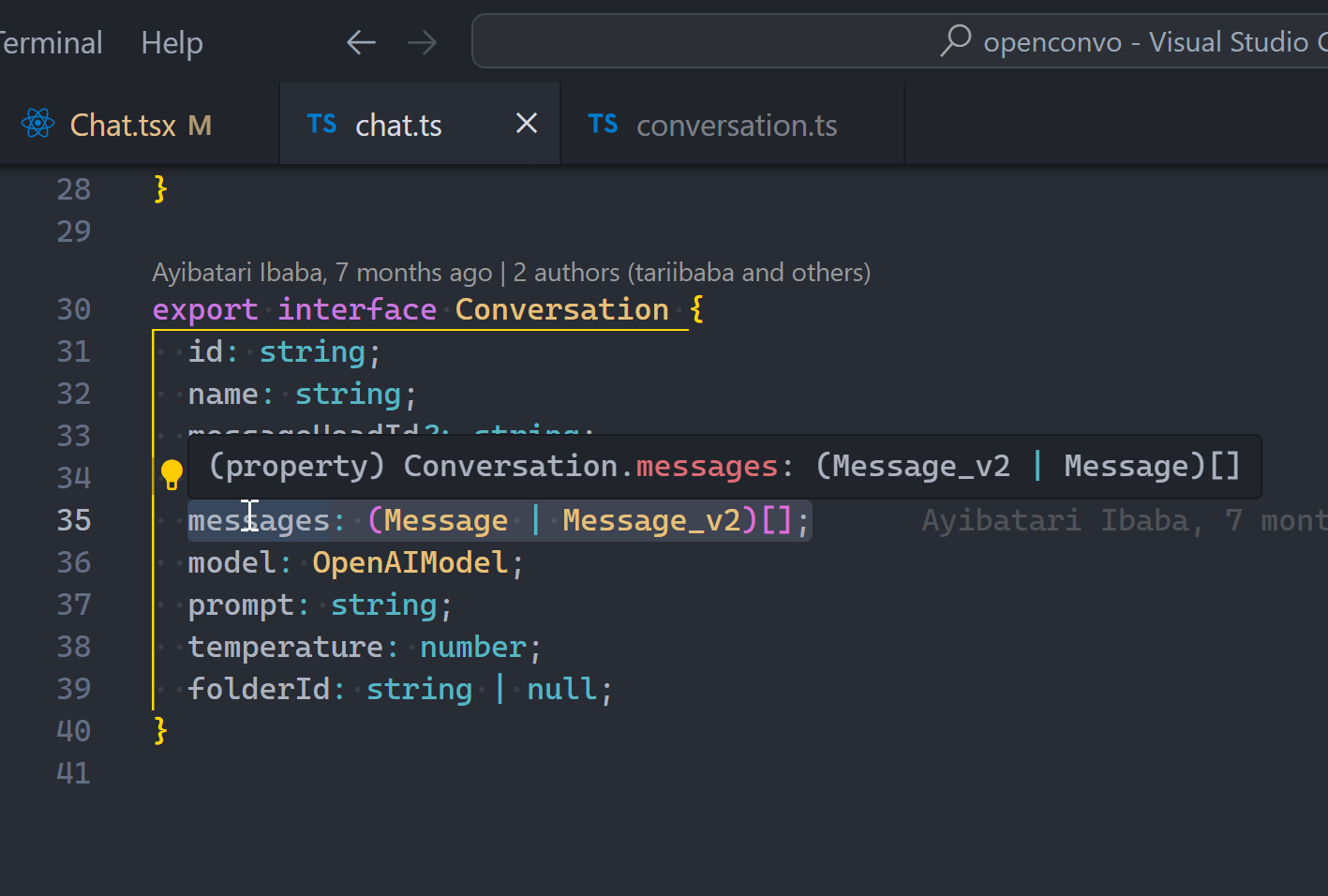
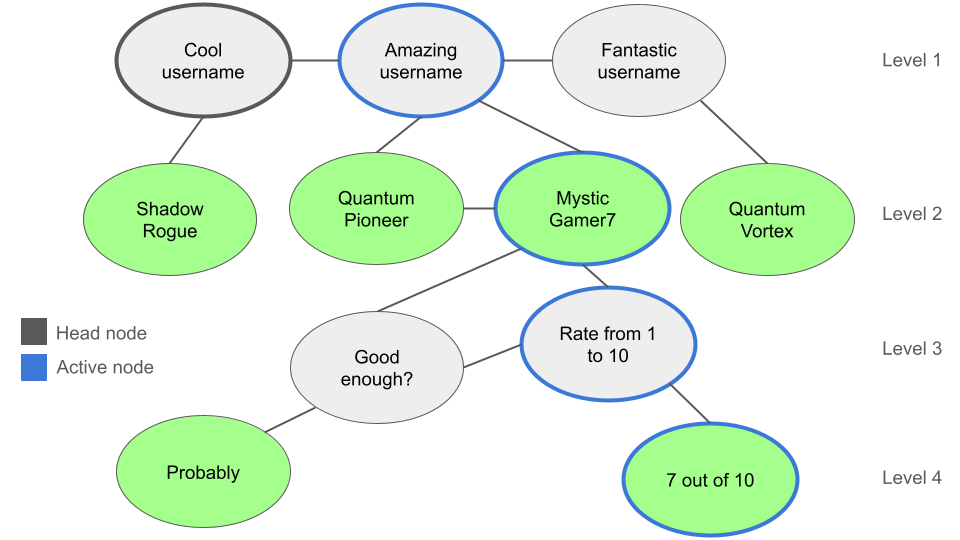
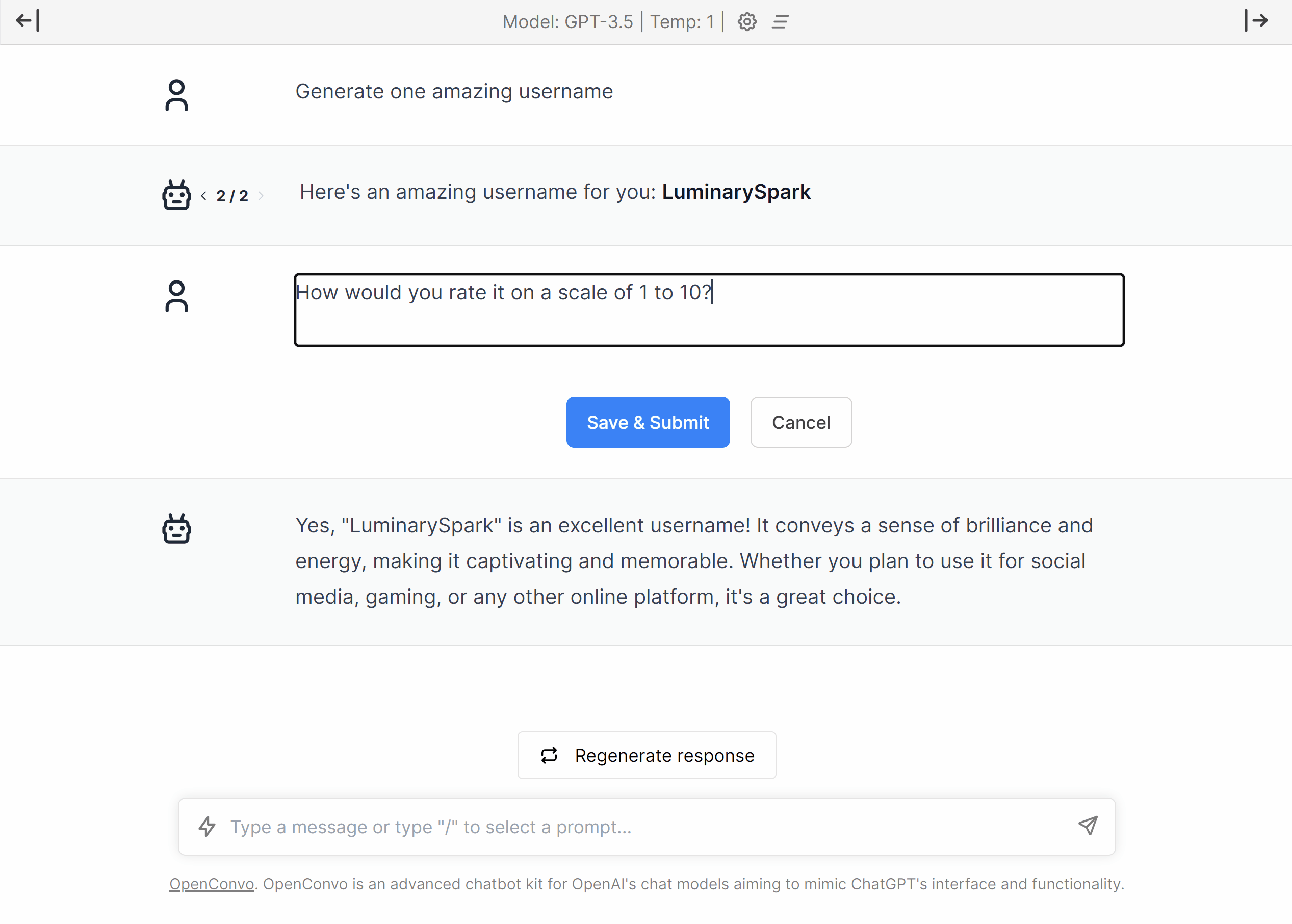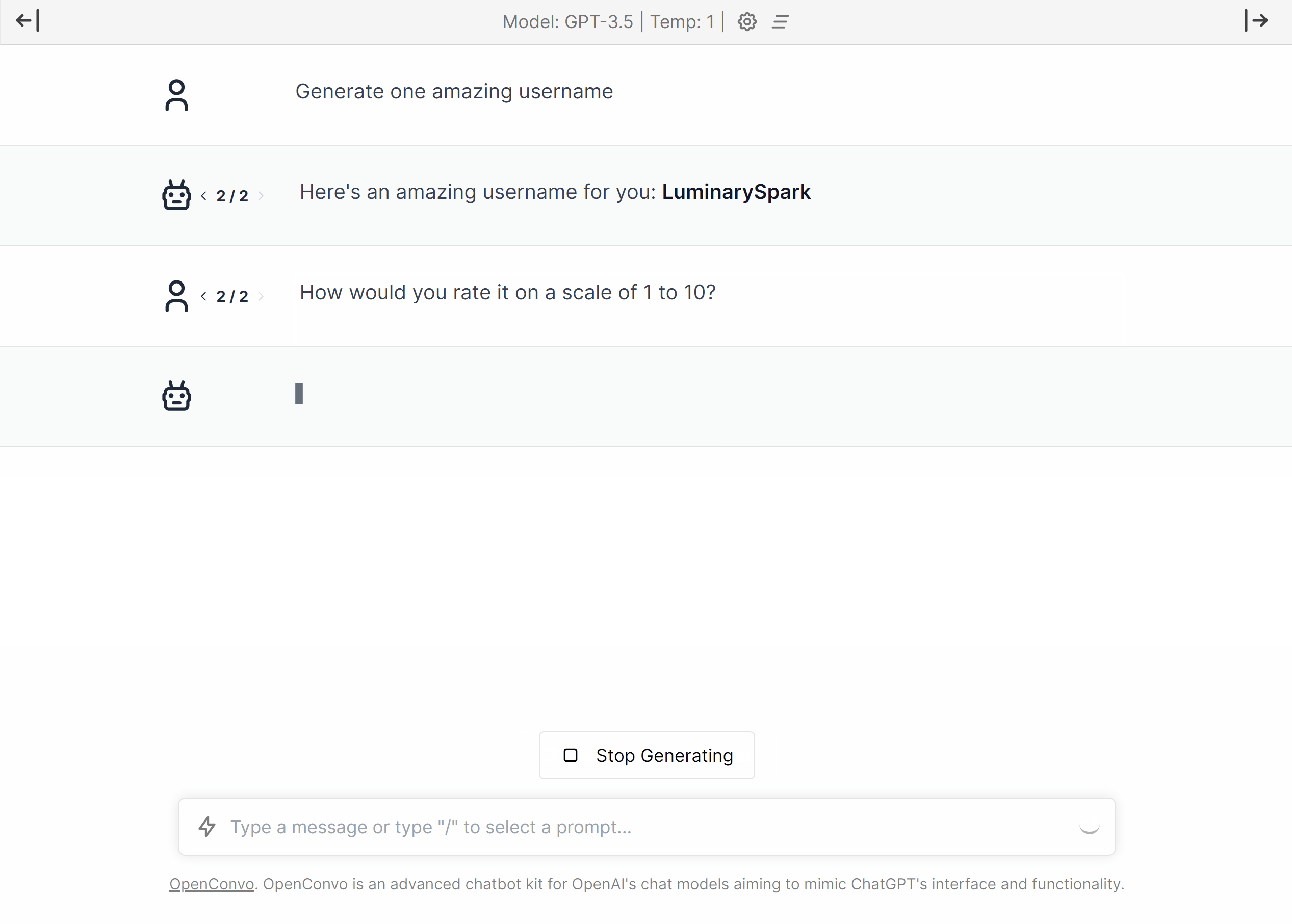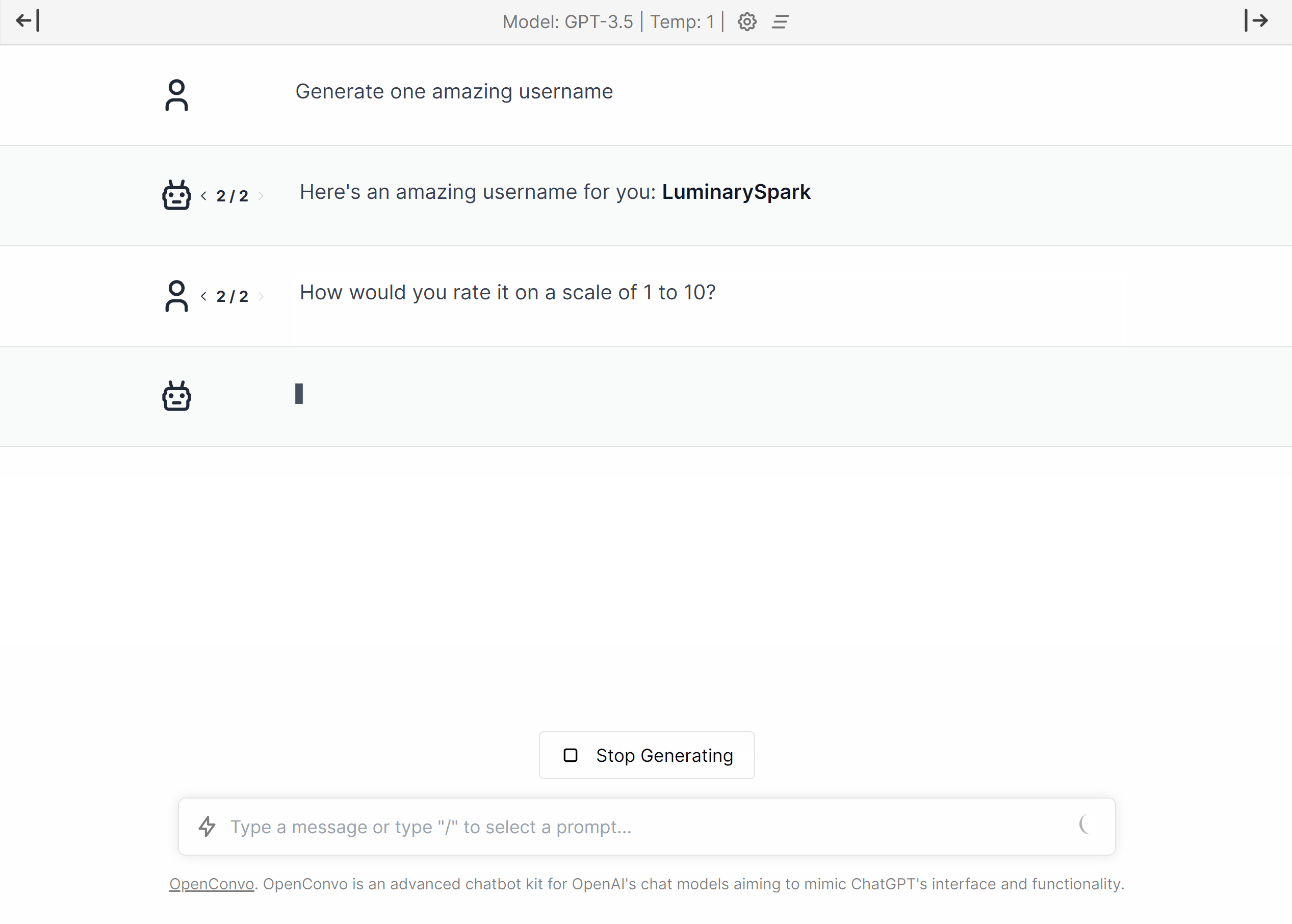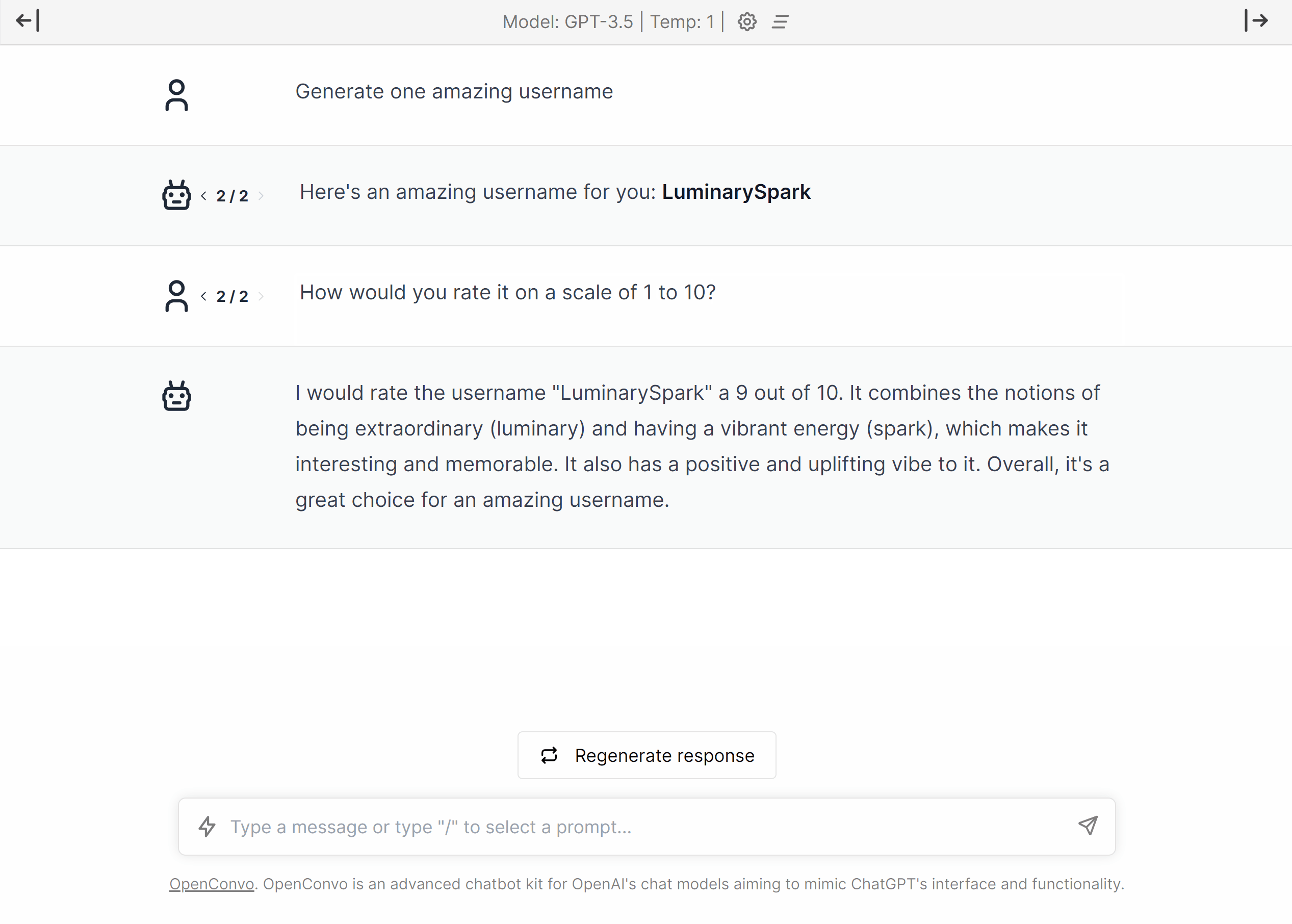
Why Devin AI can’t take your job.
Devin AI.
They claim it’s the silver bullet for all software creation, a miraculous tech outperforming every other AI model and handling real-world programming with ease.
With recent news of Nvidia CEO, Jensen Huang, confidently predicting the impending death of coding, surely this Devin AI thing must be the first nail to go in the coffin.
Mhmm.
Sounds suspiciously familiar… AutoGPT, anyone? GPT Engineer? LOL.
Oh no… before jumping on the bandwagon we need to take a closer look at the deception behind this supposed game-changer.
The first glaring issue is the lack of transparency surrounding Devin AI’s performance metrics.
Sure, they claim it’s superior, but how did they arrive at these numbers? And where’s the proof? There’s a conspicuous absence of generated source code to back up their claims.
Without this crucial evidence you can’t take their word at face value.
Can Devin AI really make a meaningful impact in a real-world repository? Doubtful. And what about limitations? Not a word. It’s as if they want us to believe Devin AI is flawless, without a single drawback.
The demos provided by Devin AI are suspect at best; They showcase its abilities but conveniently omit crucial details.
Ever notice how they never revealed the prompts inputted by the user?
If you pause the videos and examine the timestamps, you’ll find it takes hours, not the mere five minutes they lead you to believe. It’s a smoke and mirrors act designed to dazzle without substance.
And what about the demos themselves? They’re basic, rudimentary at best. Many of the problems showcased are nothing more than following a tutorial, some of which even included code snippets.
Hype over competence.

Perhaps the most concerning aspect is the lack of public testing. If Devin AI truly lives up to the hype, why not let the public put it through its paces?
The reluctance to release it for testing raises red flags and hints at a possible cash grab scheme. Business may well soon find themselves disillusioned with promises that fail to materialize.
Trusting AI blindly is a path to failure.
Even if Devin AI does possess remarkable capabilities, it’s important to remember that code still requires human understanding and review to be acceptable. Software engineering is a nuanced field with countless variables; How can an AI know it is correct when its idea of correctness is bound by its training data?
If you think AI can replace developers so easily, then you probably missing the whole point of why we code. Coding at it’s core, is not about typing and compiling. It’s not even about creating apps or websites.
Coding is about specifying the requirements of a system with zero ambiguity. It’s about expressing the solution to a problem with absolute precision.
When you type in a prompt to ChatGPT with all the vivid descriptions and (hopefully) expressive constraints, you are coding.
The difference now is the glaring ambiguity of natural language; the lack of certainty of getting exactly what you want from the AI 100% of the time. That’s why you can refine a prompt dozens of times and have absolutely nothing to show for it.
So AI can only be as good at generating code as the instructions it’s given. And describing the software you want with precision has always been the greatest challenge in software development.
If Devin AI can compel users to provide enough definitions, then perhaps it has potential. But until then, it remains an overhyped tool with limited utility.
AI’s role in programming is similar to the evolution of programming languages. As languages have progressed, programming has become more accessible. But has this led to fewer programmers? No. Instead, it has expanded the reach of programming, leading to more innovation and productivity.
Likewise AI-supported coding will enhance productivity, not replace developers. These AI models are essentially sophisticated search engines trained on vast amounts of data. They excel at common tasks but falter when faced with specific or innovative challenges. They lack the creativity and problem-solving abilities inherent in human developers.
Once again let’s not forget about reliability; AI may churn out code, but isn’t always accurate; deploying AI in critical applications without human oversight is a recipe for disaster. Developers are essential for identifying and correcting errors to ensure the integrity and functionality of the software.
Devin AI may have its uses but it’s far from the panacea it’s been made out to be. As software engineers we should embrace innovation but remain skeptical of overhyped technologies. After all, it’s our expertise and ingenuity that will continue to drive progress in the field, not flashy AI gimmicks.